Слияние частей
Что такое слияние частей в ClickHouse?
ClickHouse быстрый не только для запросов, но и для вставок, благодаря своему слою хранения, который работает аналогично LSM-деревьям:
① Вставки (в таблицы из семейства MergeTree engine) создают отсортированные, неизменяемые части данных.
② Вся обработка данных выполняется в фоновом слиянии частей.
Это делает записи данных лёгкими и высокоэффективными.
Чтобы контролировать количество частей на таблицу и реализовать ② выше, ClickHouse непрерывно сливает (по партиции) меньшие части в более крупные в фоновом режиме, пока они не достигнут сжатого размера примерно ~150 ГБ.
Следующая диаграмма иллюстрирует этот процесс фонового слияния:
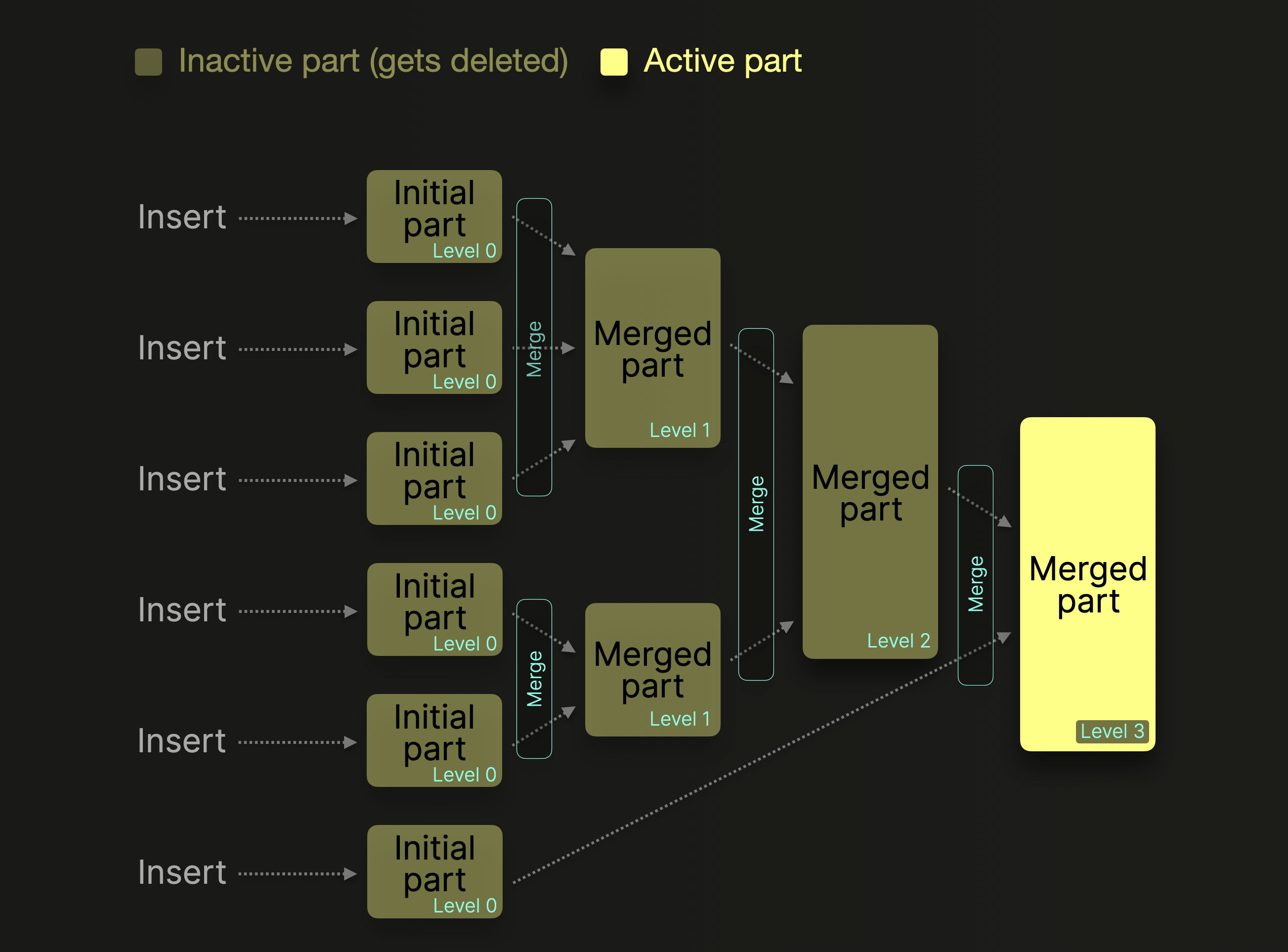
merge level части увеличивается на единицу с каждым дополнительным слиянием. Уровень 0 означает, что часть новая и ещё не была слита. Части, которые были слиты в более крупные, помечаются как неактивные и в конечном итоге удаляются после настраиваемого времени (по умолчанию 8 минут). Со временем это создает дерево слитых частей. Отсюда название дерево слияния таблицы.
Мониторинг слияний
В примерe частей таблицы мы показали, что ClickHouse отслеживает все части таблицы в системной таблице parts. Мы использовали следующий запрос для получения уровня слияния и количества хранимых строк в каждой активной части примерной таблицы:
Запускающий запрос сейчас показывает, что четыре части слились в одну финальную часть (если не было дополнительных вставок в таблицу):
В ClickHouse 24.10 была добавлена новая панель слияний в встроенные панели мониторинга. Доступная как в OSS, так и в Cloud через HTTP-обработчик /merges, мы можем использовать её для визуализации всех слияний частей для нашей примерной таблицы:
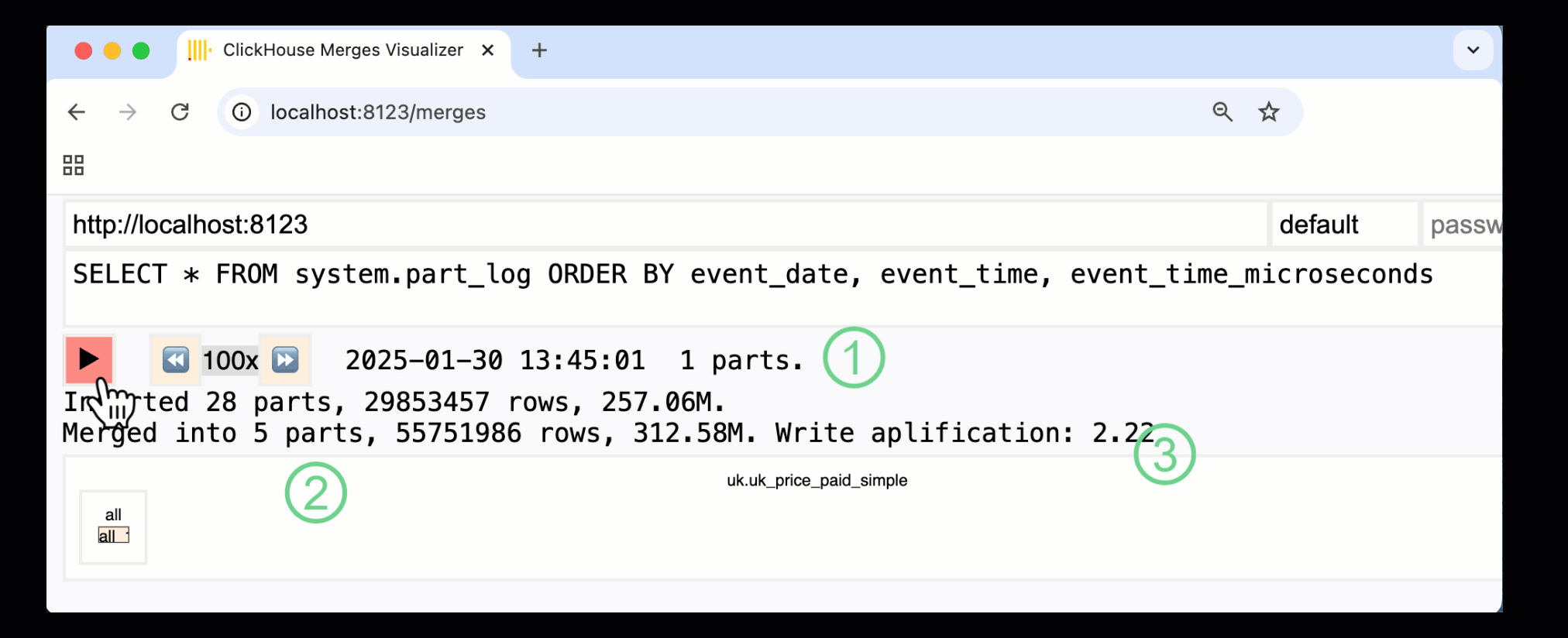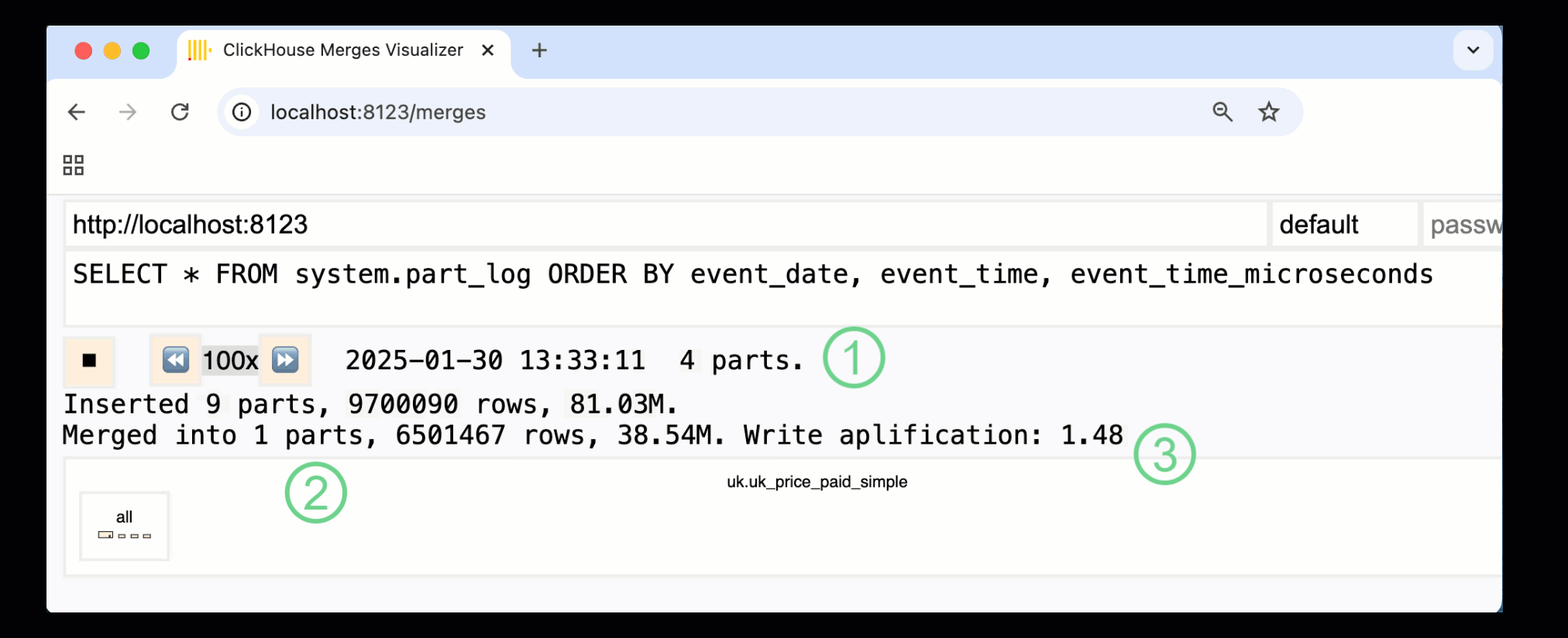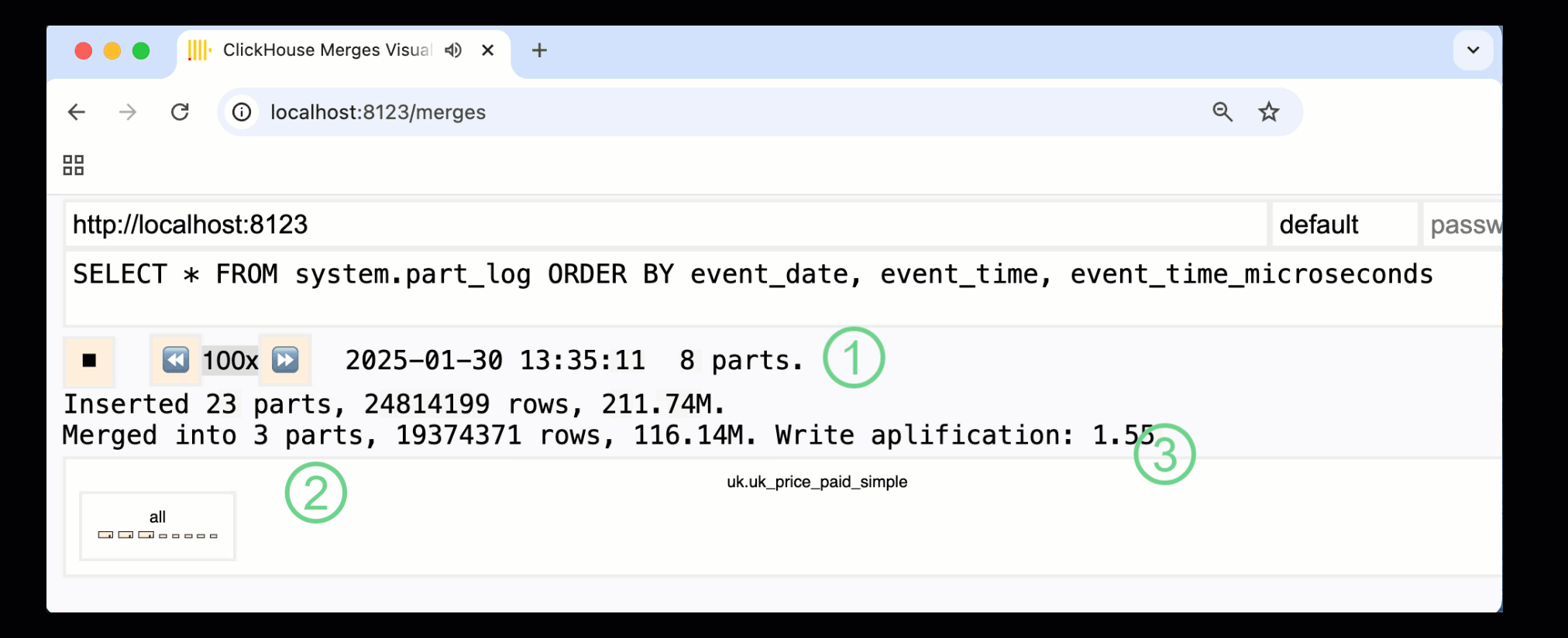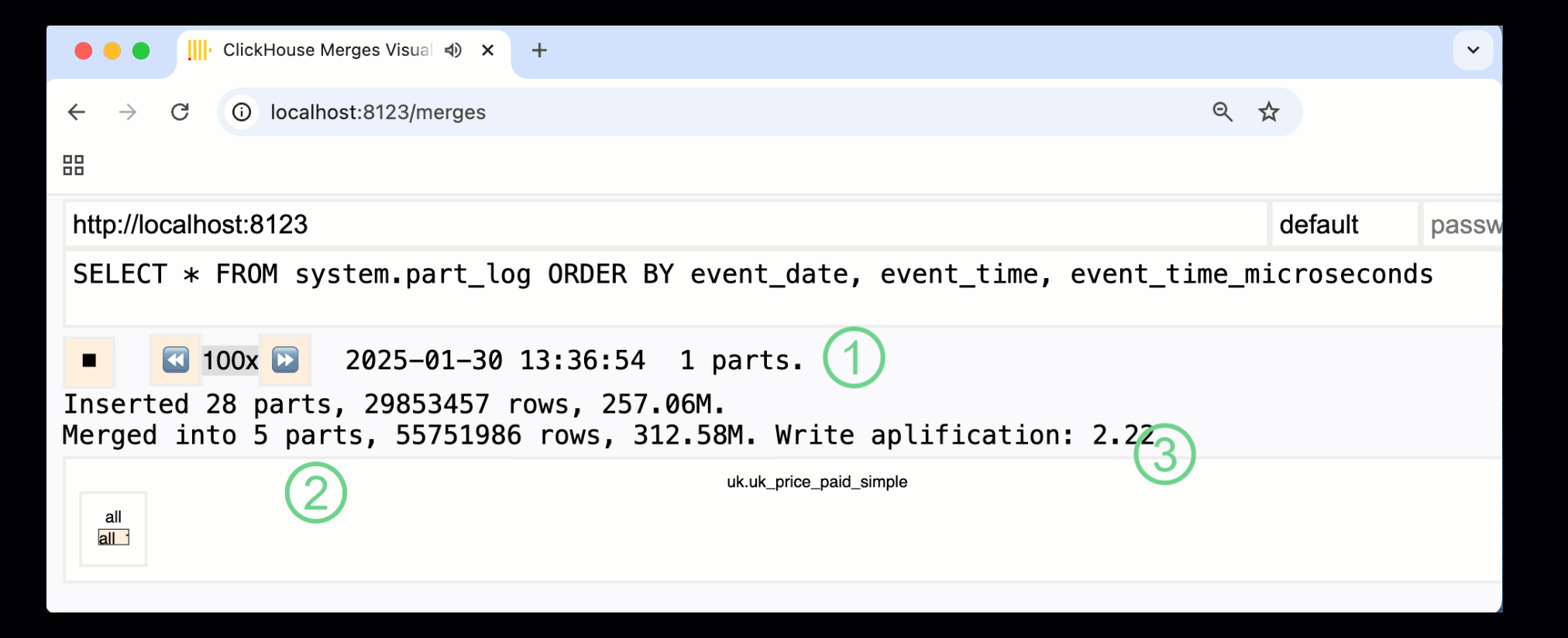
Записанная выше панель захватывает весь процесс, начиная с начальных вставок данных и заканчивая финальным слиянием в одну часть:
① Количество активных частей.
② Слияния частей, визуально представленные с помощью прямоугольников (размер отражает размер части).
Параллельные слияния
Один сервер ClickHouse использует несколько фоновых потоков слияния для выполнения параллельных слияний частей:
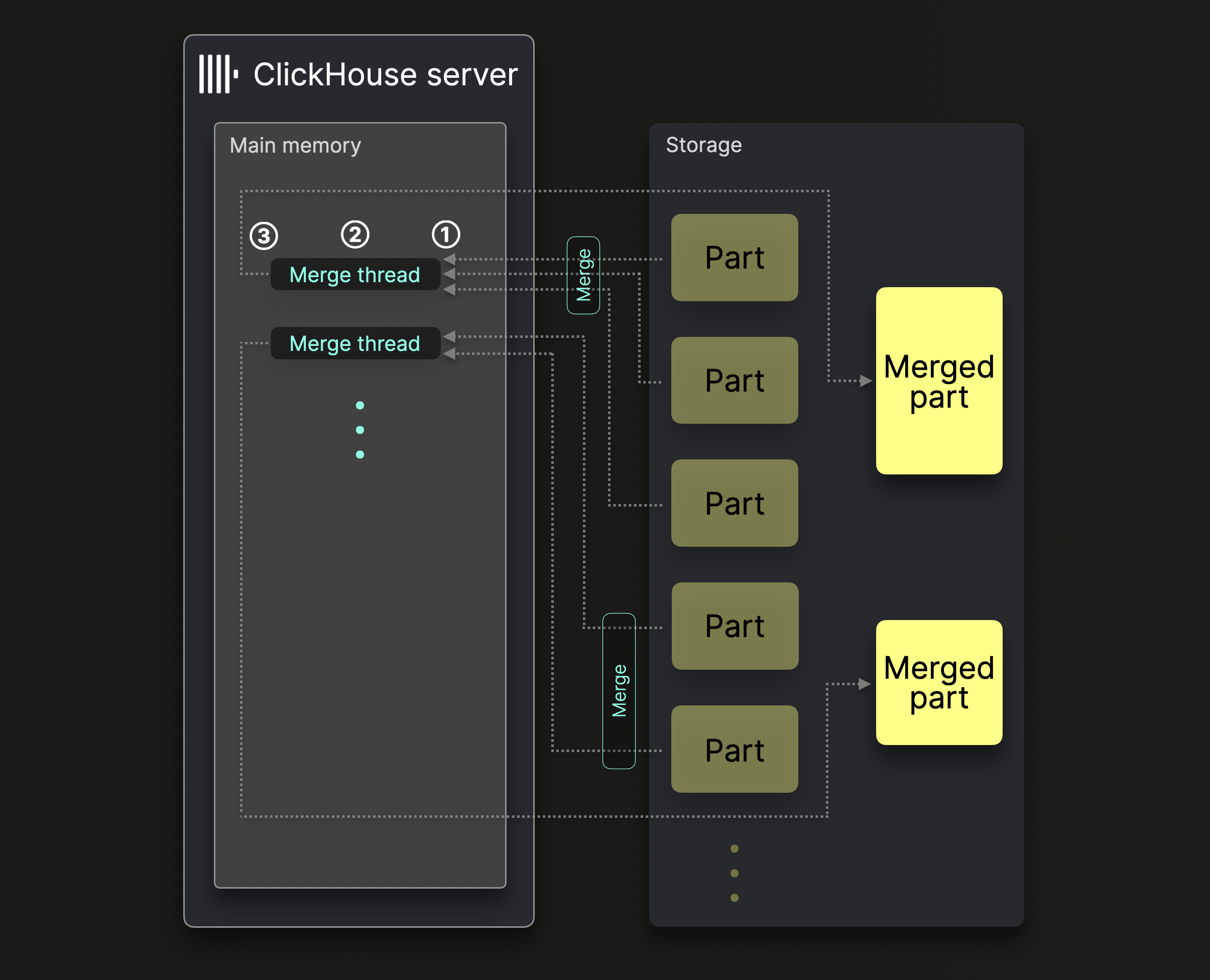
Каждый поток слияния выполняет цикл:
① Определяет, какие части слить следующими, и загружает эти части в память.
② Сливает части в памяти в большую часть.
③ Записывает слитую часть на диск.
Перейти к ①
Обратите внимание, что увеличение количества ядер CPU и объема RAM позволяет увеличить пропускную способность фоновых слияний.
Оптимизированные по памяти слияния
ClickHouse не обязательно загружает все части, которые будут слиты, в память одновременно, как было показано в предыдущем примере. Основываясь на нескольких факторах, и для снижения потребления памяти (путем жертвы скоростью слияния), так называемые вертикальные слияния загружают и сливают части блоками вместо сразу.
Механика слияния
Следующая диаграмма иллюстрирует, как один фоновый поток слияния в ClickHouse сливает части (по умолчанию, без вертикального слияния):
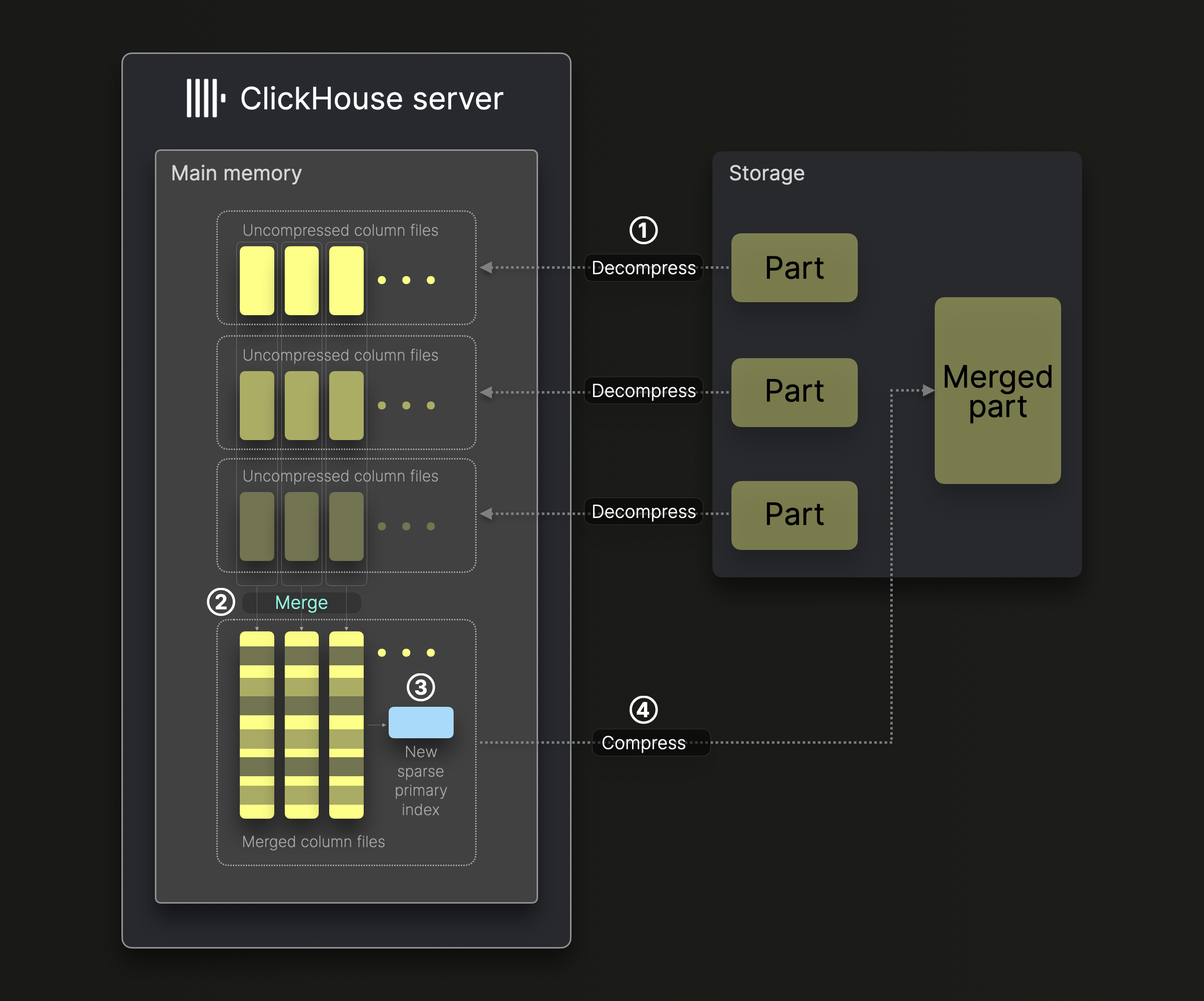
Слияние частей выполняется в несколько этапов:
① Декомпрессия и загрузка: Сжатые бинарные файлы колонок из частей для слияния декомпрессируются и загружаются в память.
② Слияние: Данные сливаются в более крупные файлы колонок.
③ Индексирование: Генерируется новый разреженный первичный индекс для слитых файлов колонок.
④ Сжатие и хранение: Новые файлы колонок и индекс сжимаются и сохраняются в новом каталоге, представляющем слитую часть данных.
Дополнительные метаданные в частях данных, такие как вторичные индексы пропуска данных, статистика по колонкам, контрольные суммы и минимальные/максимальные индексы, также воссоздаются на основе слитых файлов колонок. Мы опустили эти детали ради простоты.
Механика шага ② зависит от конкретного движка MergeTree, поскольку разные движки обрабатывают слияние по-разному. Например, строки могут агрегироваться или заменяться, если устарели. Как уже упоминалось, этот подход переносит всю обработку данных на фоновые слияния, обеспечивая супершвидкие вставки благодаря облегчению операций записи.
Далее мы кратко обрисуем механику слияния специфичных движков в семействе MergeTree.
Стандартные слияния
Следующая диаграмма иллюстрирует, как части в стандартной MergeTree таблице сливаются:
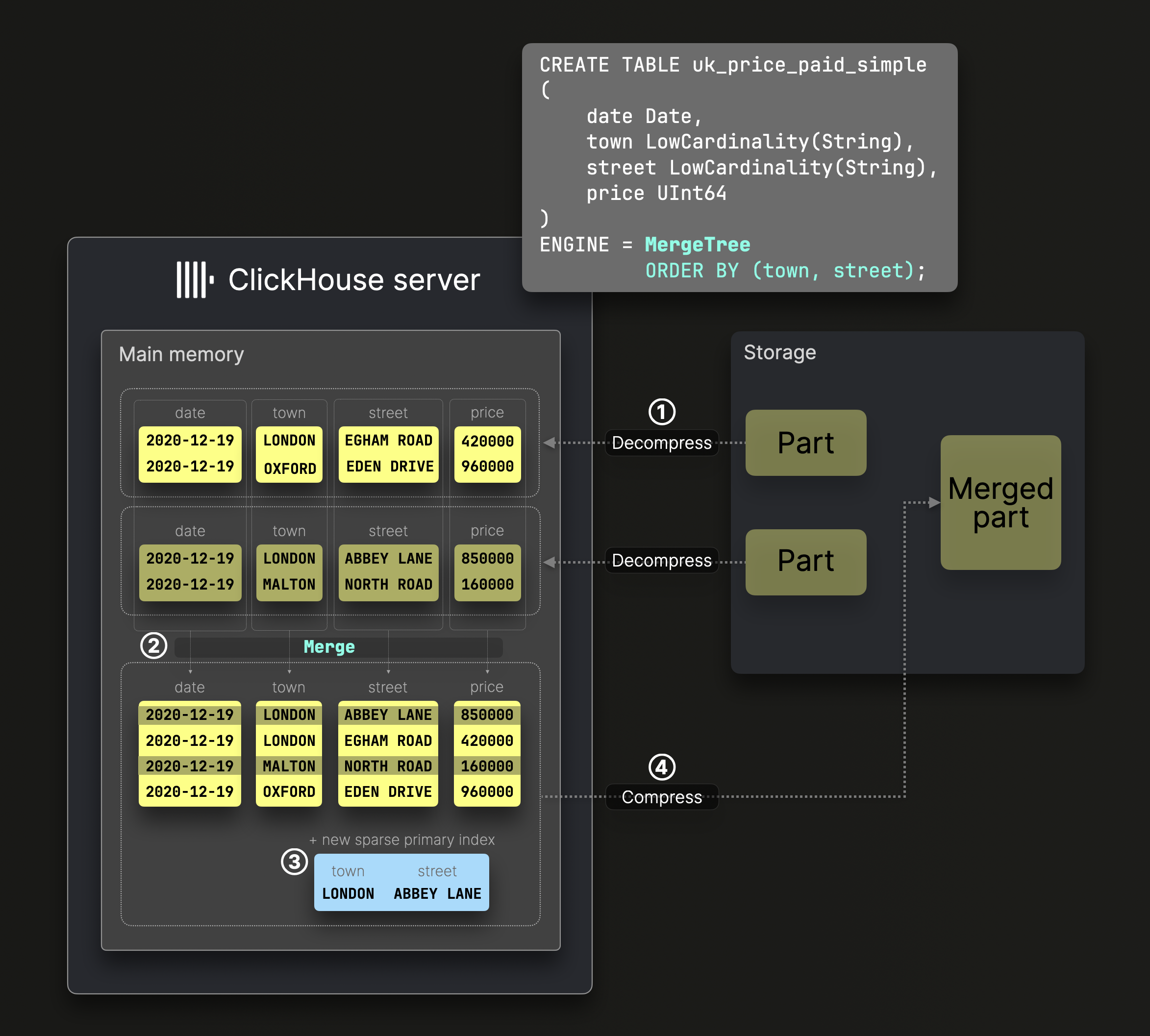
DDL оператор на диаграмме выше создает таблицу MergeTree с ключом сортировки (town, street), что означает, что данные на диске отсортированы по этим колонкам, и разреженный первичный индекс создается соответственно.
Сначала ① декомпрессированные, предсортированные колонки таблицы ② сливаются, сохраняя глобальный порядок сортировки таблицы, определяемый ключом сортировки таблицы, ③ создается новый разреженный первичный индекс, и ④ слитые файлы колонок и индекс сжимаются и хранятся как новая часть данных на диске.
Заменяющие слияния
Слияния частей в таблице ReplacingMergeTree работают аналогично стандартным слияниям, но сохраняется только самая последняя версия каждой строки, а старые версии отбрасываются:
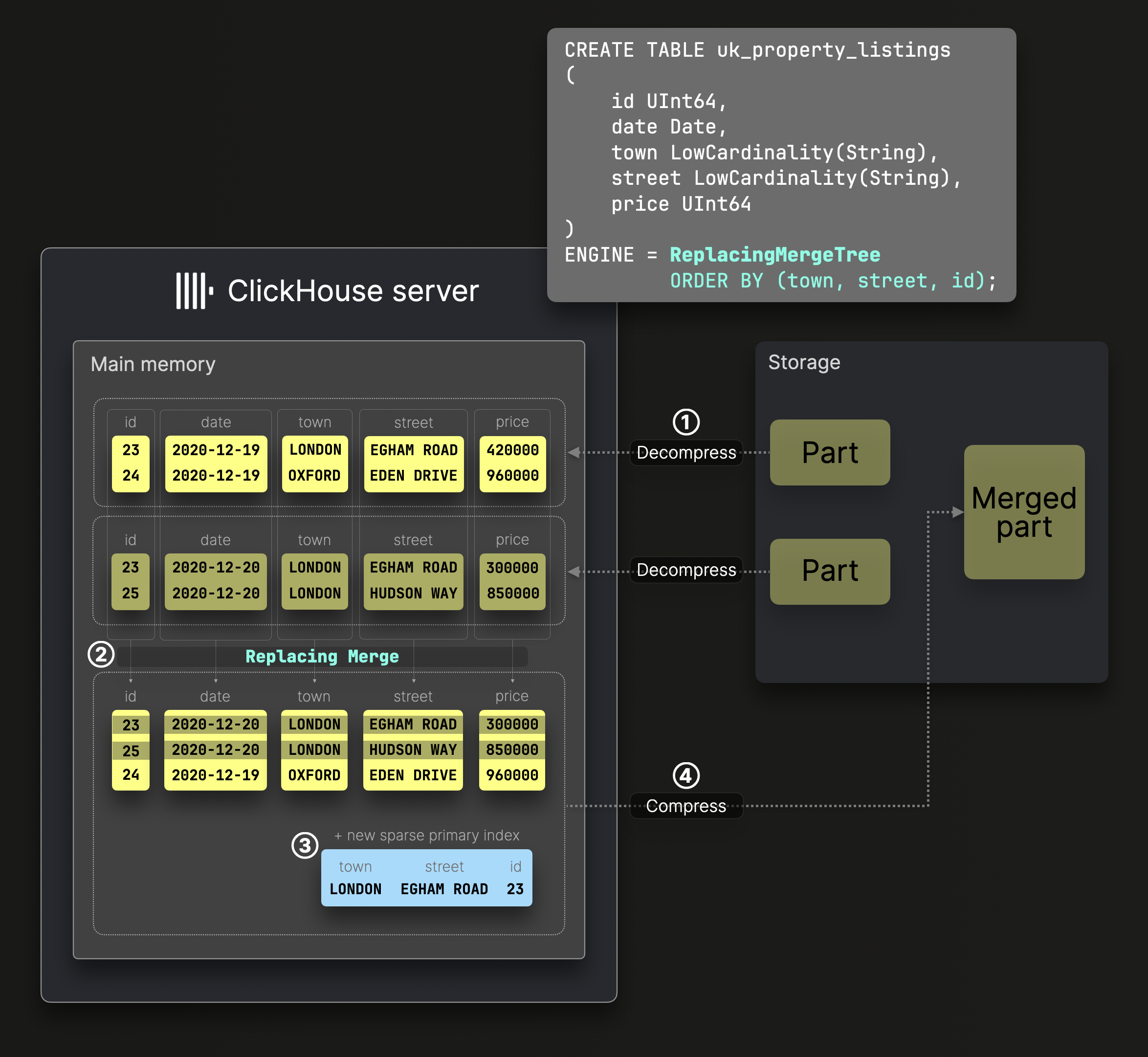
DDL оператор на диаграмме выше создает таблицу ReplacingMergeTree с ключом сортировки (town, street, id), что значит, что данные на диске отсортированы по этим колонкам, с разреженным первичным индексом созданным соответственно.
Слияние ② работает аналогично стандартной таблице MergeTree, объединяя декомпрессированные, предсортированные колонки, сохраняя глобальный порядок сортировки.
Однако ReplacingMergeTree удаляет дубликаты строк с одинаковым ключом сортировки, сохраняя только самую последнюю строку на основе времени создания содержащей её части.
Суммирующие слияния
Числовые данные автоматически суммируются во время слияний частей из таблицы SummingMergeTree:
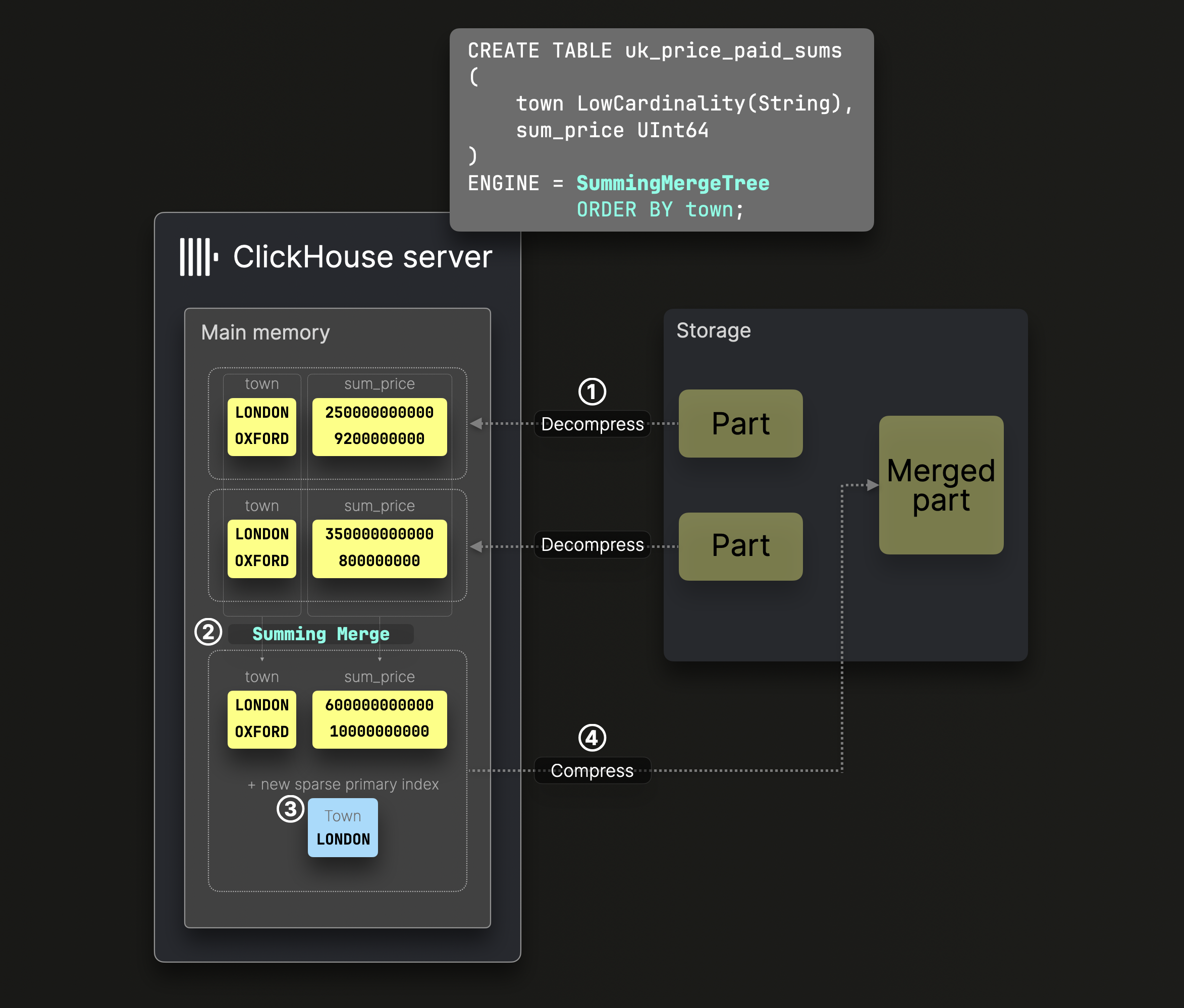
DDL оператор на диаграмме выше определяет таблицу SummingMergeTree с town в качестве ключа сортировки, что означает, что данные на диске отсортированы по этой колонке и соответственно создается разреженный первичный индекс.
На этапе ② слияния ClickHouse заменяет все строки с одинаковым ключом сортировки одной строкой, суммируя значения числовых колонок.
Агрегирующие слияния
Пример таблицы SummingMergeTree выше является специализированным вариантом таблицы AggregatingMergeTree, позволяющим автоматическое инкрементное преобразование данных при применении любой из 90+ агрегатных функции во время слияний частей:
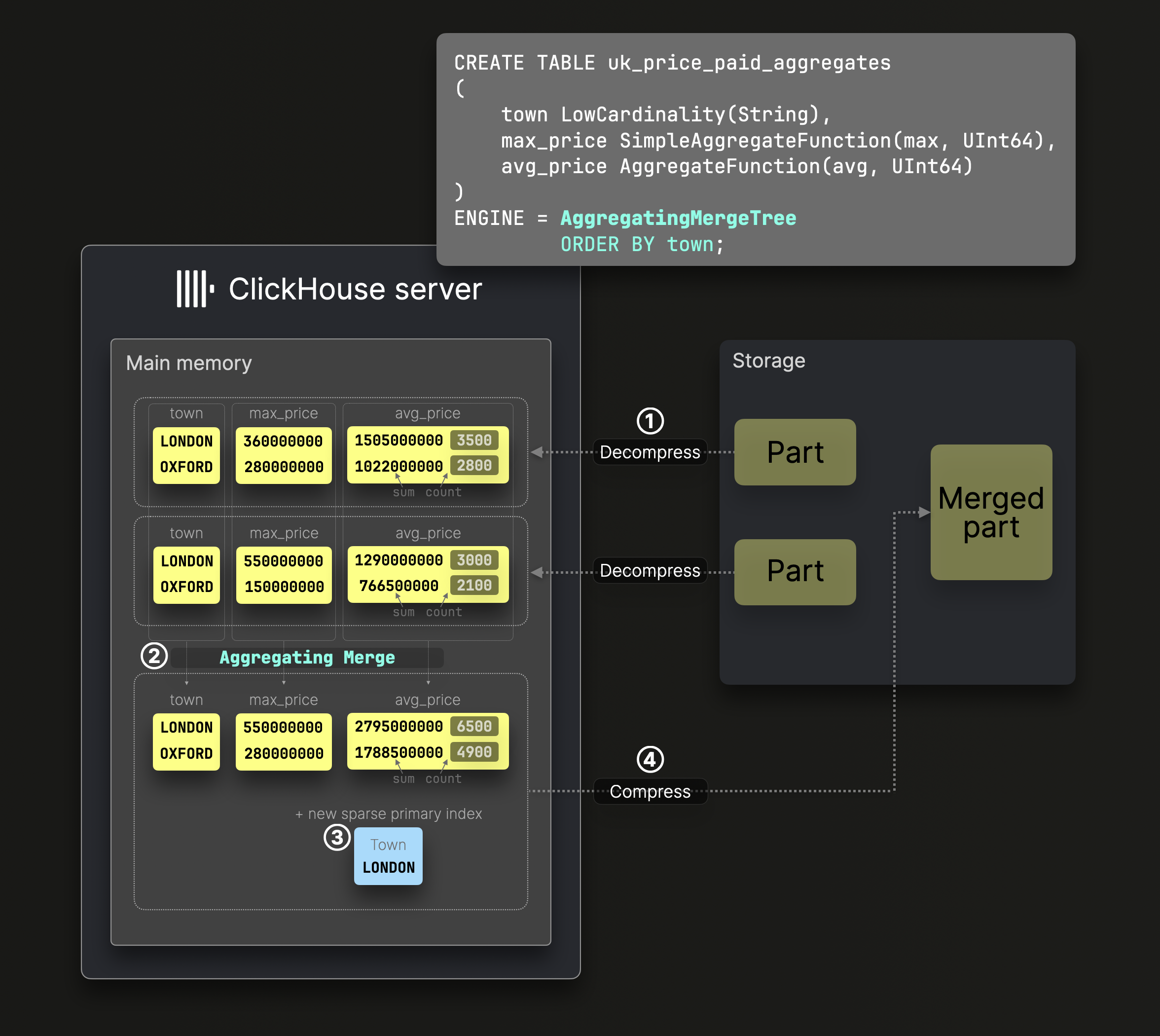
DDL оператор на диаграмме выше создает таблицу AggregatingMergeTree с town в качестве ключа сортировки, гарантируя, что данные упорядочены по этой колонке на диске и создается соответствующий разреженный первичный индекс.
Во время ② слияния ClickHouse заменяет все строки с одинаковым ключом сортировки одной строкой, хранящей частичные состояния агрегации (например, sum и count для avg()). Эти состояния обеспечивают точные результаты через инкрементные фоновые слияния.