Понимание выполнения запросов с помощью анализатора
ClickHouse обрабатывает запросы чрезвычайно быстро, но выполнение запроса — это не простая задача. Давайте попробуем понять, как выполняется запрос SELECT. Чтобы проиллюстрировать это, добавим некоторые данные в таблицу в ClickHouse:
Теперь, когда у нас есть некоторые данные в ClickHouse, мы хотим выполнить несколько запросов и понять их выполнение. Выполнение запроса делится на множество шагов. Каждый шаг выполнения запроса можно проанализировать и устранить неполадки с помощью соответствующего запроса EXPLAIN. Эти шаги обобщены на диаграмме ниже:
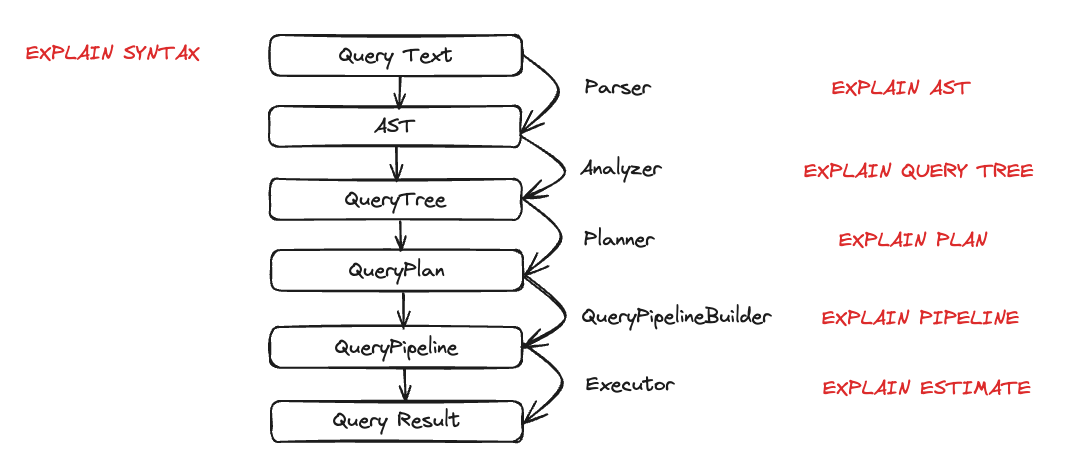
Давайте посмотрим на каждую сущность в действии во время выполнения запроса. Мы возьмем несколько запросов и затем проанализируем их с помощью оператора EXPLAIN.
Парсер
Цель парсера — преобразовать текст запроса в АСТ (Абстрактное Синтаксисное Дерево). Этот шаг можно визуализировать с помощью EXPLAIN AST:
Вывод — это Абстрактное Синтаксисное Дерево, которое можно визуализировать, как показано ниже:
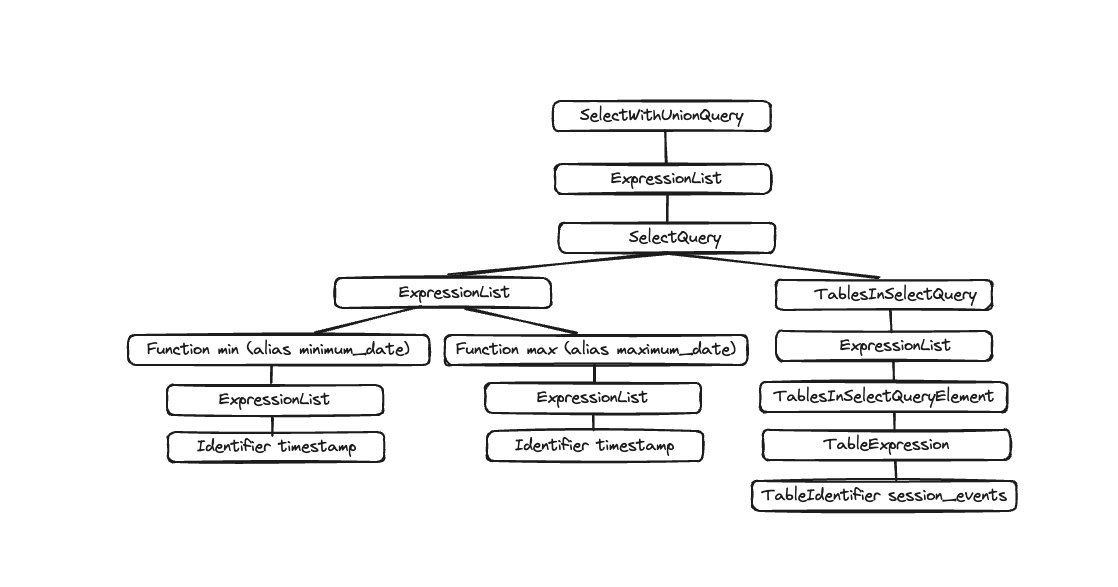
Каждый узел имеет соответствующих детей, и все дерево представляет собой общую структуру вашего запроса. Это логическая структура, помогающая обработке запроса. С точки зрения конечного пользователя (если его не интересует выполнение запроса) это не слишком полезно; этот инструмент в основном используется разработчиками.
Анализатор
ClickHouse в настоящее время имеет две архитектуры для Анализатора. Вы можете использовать старую архитектуру, установив: enable_analyzer=0. Новая архитектура включена по умолчанию. Здесь мы опишем только новую архитектуру, так как старая будет признана устаревшей, как только новый анализатор станет общедоступным.
Новая архитектура должна предоставить нам лучшую основу для улучшения производительности ClickHouse. Однако, поскольку она является фундаментальным компонентом шагов обработки запросов, она также может оказать негативное влияние на некоторые запросы, и существуют известные несовместимости. Вы можете вернуться к старому анализатору, изменив настройку enable_analyzer на уровне запроса или пользователя.
Анализатор — это важный шаг выполнения запроса. Он принимает АСТ и преобразует его в дерево запроса. Главное преимущество дерева запроса по сравнению с АСТ заключается в том, что многие компоненты будут разрешены, например, хранилище. Мы точно знаем, из какой таблицы читать, также разрешаются псевдонимы, и дерево знает различные используемые типы данных. Со всеми этими преимуществами анализатор может применять оптимизации. Способ, которым работают эти оптимизации, — это "проходы". Каждый проход будет искать различные оптимизации. Вы можете увидеть все проходы здесь, давайте посмотрим это на практике с нашим предыдущим запросом:
Между двумя выполнениями вы можете увидеть разрешение псевдонимов и проекций.
Планировщик
Планировщик берет дерево запроса и строит из него план запроса. Дерево запроса говорит нам, что мы хотим сделать с конкретным запросом, а план запроса говорит, как мы это будем делать. Дополнительные оптимизации будут выполнены как часть плана запроса. Вы можете использовать EXPLAIN PLAN или EXPLAIN, чтобы увидеть план запроса (EXPLAIN выполнит EXPLAIN PLAN).
Хотя это дает нам некоторую информацию, мы можем получить больше. Например, возможно, мы хотим узнать имя столбца, по которому нам нужны проекции. Вы можете добавить заголовок к запросу:
Теперь вы знаете имена столбцов, которые необходимо создать для последней Проекции (minimum_date, maximum_date и percentage), но вы также можете захотеть иметь подробности всех действий, которые необходимо выполнить. Вы можете сделать это, установив actions=1.
Теперь вы можете видеть все входные данные, функции, псевдонимы и типы данных, которые используются. Вы можете увидеть некоторые оптимизации, которые планировщик собирается применить здесь.
Конвейер запросов
Конвейер запросов генерируется из плана запроса. Конвейер запросов очень похож на план запроса, с той разницей, что это не дерево, а граф. Он подчеркивает, как ClickHouse собирается выполнять запрос и какие ресурсы будут использоваться. Анализ конвейера запросов очень полезен для выявления узких мест в терминах входных/выходных данных. Давайте возьмем наш предыдущий запрос и посмотрим на выполнение конвейера запросов:
В скобках указан шаг плана запроса, а рядом — процессор. Это отличная информация, но поскольку это граф, было бы удобно визуализировать его как таковой. У нас есть настройка graph, которую мы можем установить в 1 и указать формат вывода как TSV:
Вы можете скопировать этот вывод и вставить его сюда, и это сгенерирует следующий график:
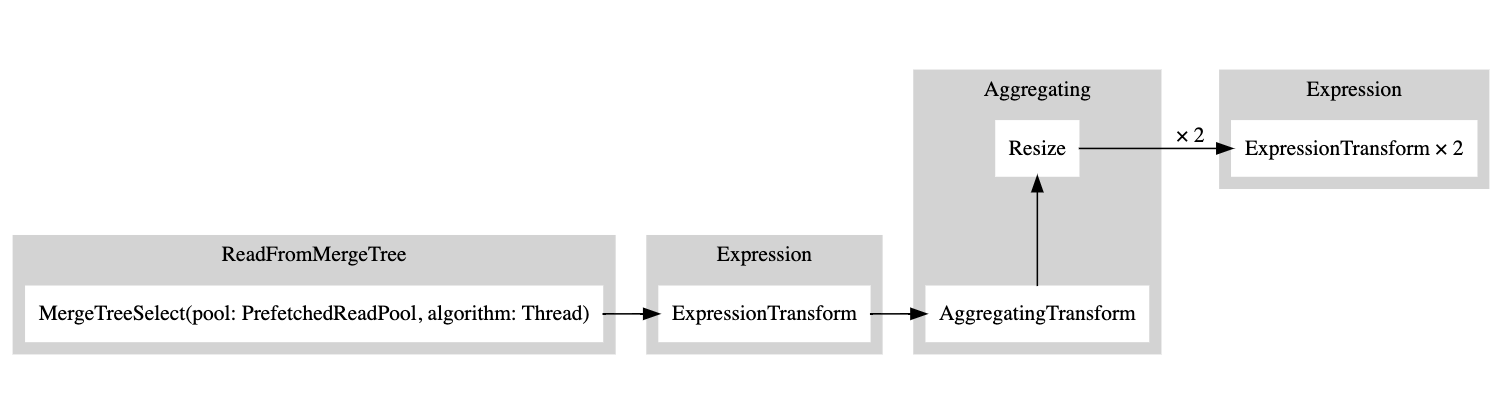
Белый прямоугольник соответствует узлу конвейера, серый прямоугольник соответствует шагам плана запроса, а x, за которым следует число, соответствует количеству входов/выходов, которые используются. Если вы не хотите видеть их в компактной форме, вы всегда можете добавить compact=0:

Почему ClickHouse не читает из таблицы с использованием нескольких потоков? Давайте попробуем добавить больше данных в нашу таблицу:
Теперь давайте снова выполним наш запрос EXPLAIN:

Таким образом, исполнитель решил не параллелизировать операции, потому что объем данных был недостаточно высок. Добавив больше строк, исполнитель затем решил использовать несколько потоков, как показано на графике.
Исполнитель
Наконец, последний шаг выполнения запроса выполняет исполнитель. Он берет конвейер запроса и выполняет его. Существуют различные типы исполнителей, в зависимости от того, выполняете ли вы SELECT, INSERT или INSERT SELECT.