Параллельные реплики
Введение
ClickHouse обрабатывает запросы чрезвычайно быстро, но как эти запросы распределяются и параллелизуются между несколькими серверами?
В этом руководстве мы сначала обсудим, как ClickHouse распределяет запрос по нескольким шардам через распределенные таблицы, а затем как запрос может использовать несколько реплик для своего выполнения.
Шардированная архитектура
В архитектуре с отсутствием общей памяти кластеры обычно делятся на несколько шардов, каждый из которых содержит подмножество общих данных. Распределенная таблица располагается над этими шардами, предоставляя единый взгляд на полные данные.
Чтения могут быть направлены в локальную таблицу. Выполнение запроса будет происходить только на указанном шарде, или он может быть отправлен в распределенную таблицу, и в этом случае каждый шард выполнит заданные запросы. Сервер, на котором был запрошен доступ к распределенной таблице, агрегирует данные и возвращает ответ клиенту:
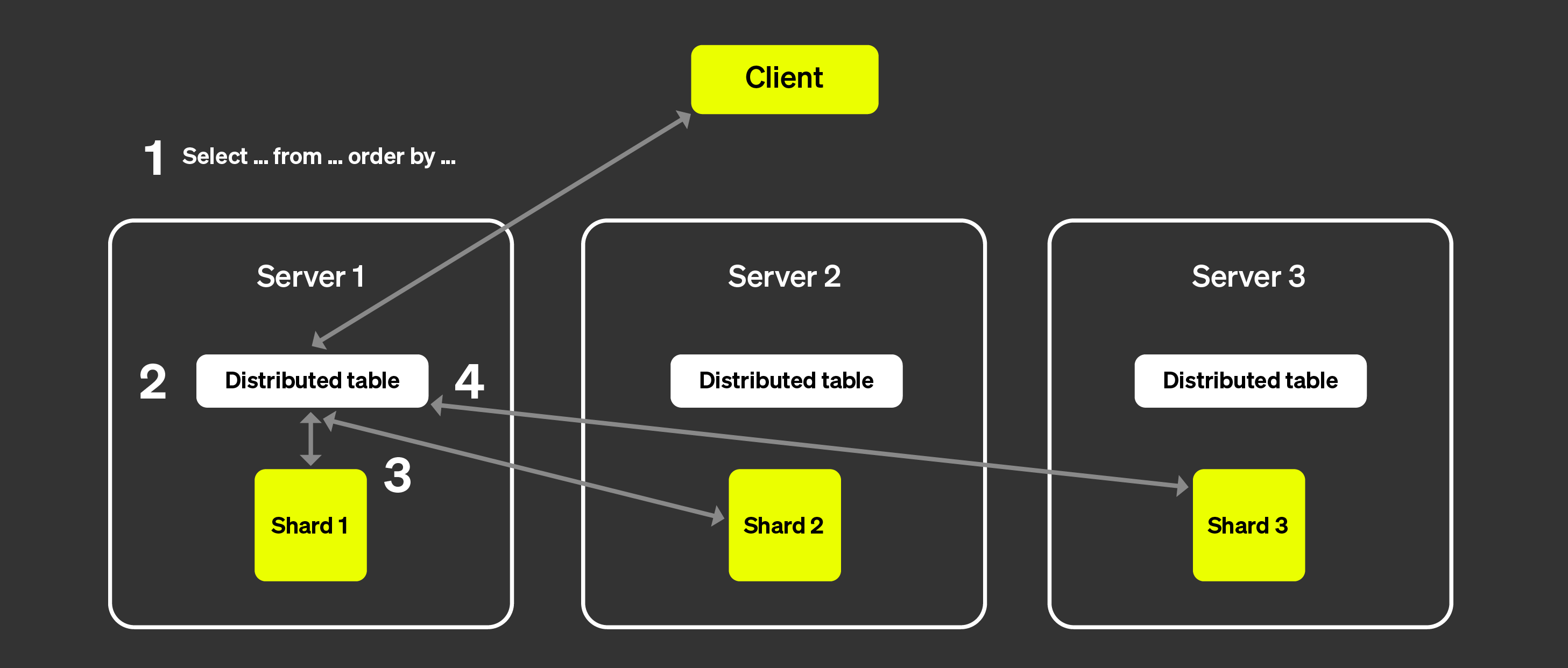
На рисунке выше визуализируется, что происходит, когда клиент запрашивает распределенную таблицу:
Запрос SELECT отправляется в распределенную таблицу на узел произвольно (через стратегию round-robin или после маршрутизации на определенный сервер балансировщиком нагрузки). Этот узел теперь будет действовать как координатор.
Узел находит каждый шард, который должен выполнить запрос, с помощью информации, указанной в распределенной таблице, и запрос отправляется каждому шард.
Каждый шард считывает, фильтрует и агрегирует данные локально, а затем отправляет обратно объединяемое состояние координатору.
Координирующий узел объединяет данные и затем отправляет ответ клиенту.
Когда мы добавляем реплики в mix, процесс довольно похож, единственное различие состоит в том, что только одна реплика из каждого шарда выполнит запрос. Это означает, что больше запросов может быть обработано параллельно.
Не-шардированная архитектура
ClickHouse Cloud имеет совершенно другую архитектуру, чем представленная выше. (См. "Архитектура ClickHouse Cloud" для получения дополнительных сведений). С разделением вычислений и хранения, и с практически неограниченным объемом хранения необходимость в шардировании становится менее важной.
На рисунке ниже показана архитектура ClickHouse Cloud:
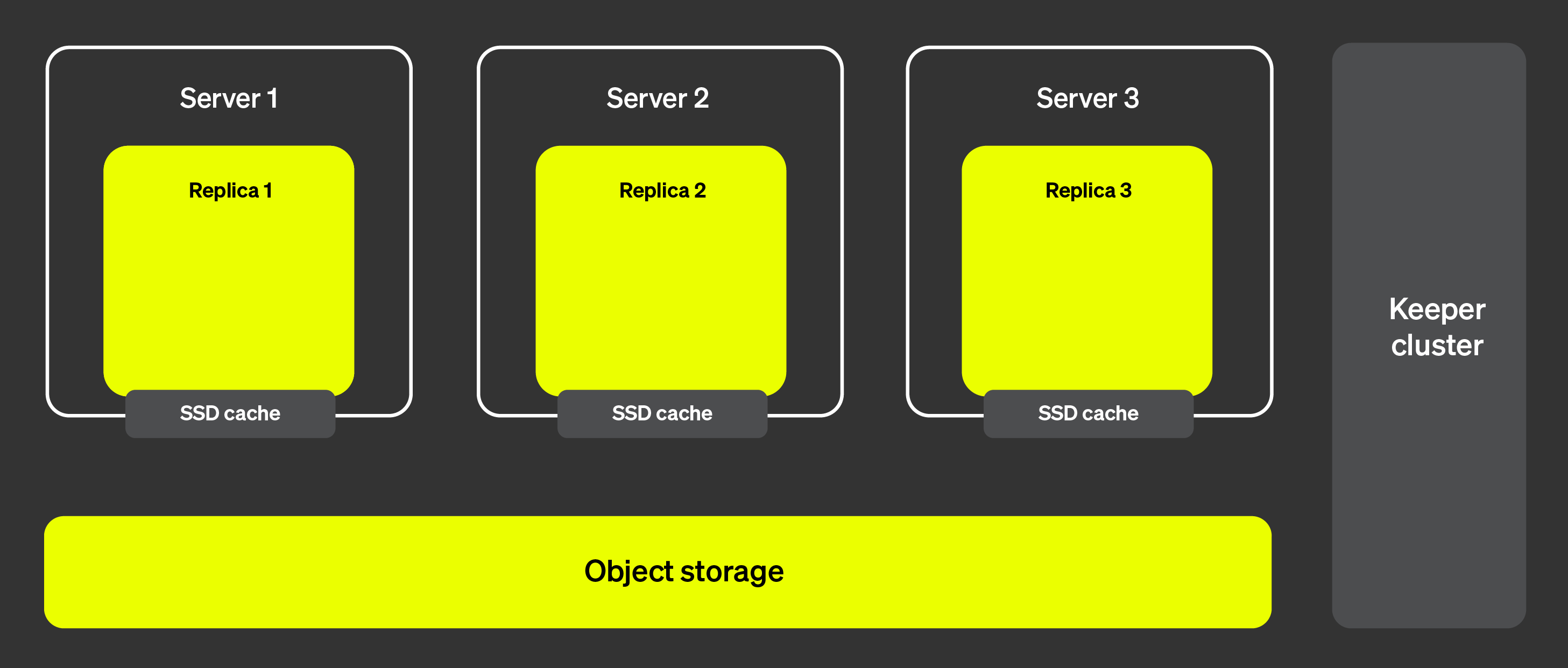
Эта архитектура позволяет нам добавлять и удалять реплики почти мгновенно, обеспечивая очень высокую масштабируемость кластера. Кластер ClickHouse Keeper (показан справа) обеспечивает наличие единого источника правды для метаданных. Реплики могут извлекать метаданные из кластера ClickHouse Keeper и все поддерживать одинаковые данные. Сами данные хранятся в объектном хранилище, а кеш SSD позволяет ускорить запросы.
Но как мы теперь можем распределить выполнение запросов между несколькими серверами? В шардированной архитектуре это было довольно очевидно, поскольку каждый шард мог фактически выполнить запрос на подмножестве данных. Как это работает при отсутствии шардирования?
Введение в параллельные реплики
Чтобы параллелизовать выполнение запросов через несколько серверов, нам сначала нужно назначить один из наших серверов координатором. Координатор — это тот, кто создает список задач, которые необходимо выполнить, обеспечивает их выполнение, агрегирует и возвращает результат клиенту. Как и в большинстве распределенных систем, эту роль будет исполнять узел, который получает начальный запрос. Мы также должны определить единицу работы. В шардированной архитектуре единицей работы является шард, подмножество данных. В параллельных репликах мы будем использовать небольшую часть таблицы, которая называется гранулы, в качестве единицы работы.
Теперь давайте посмотрим, как это работает на практике с помощью рисунка ниже:
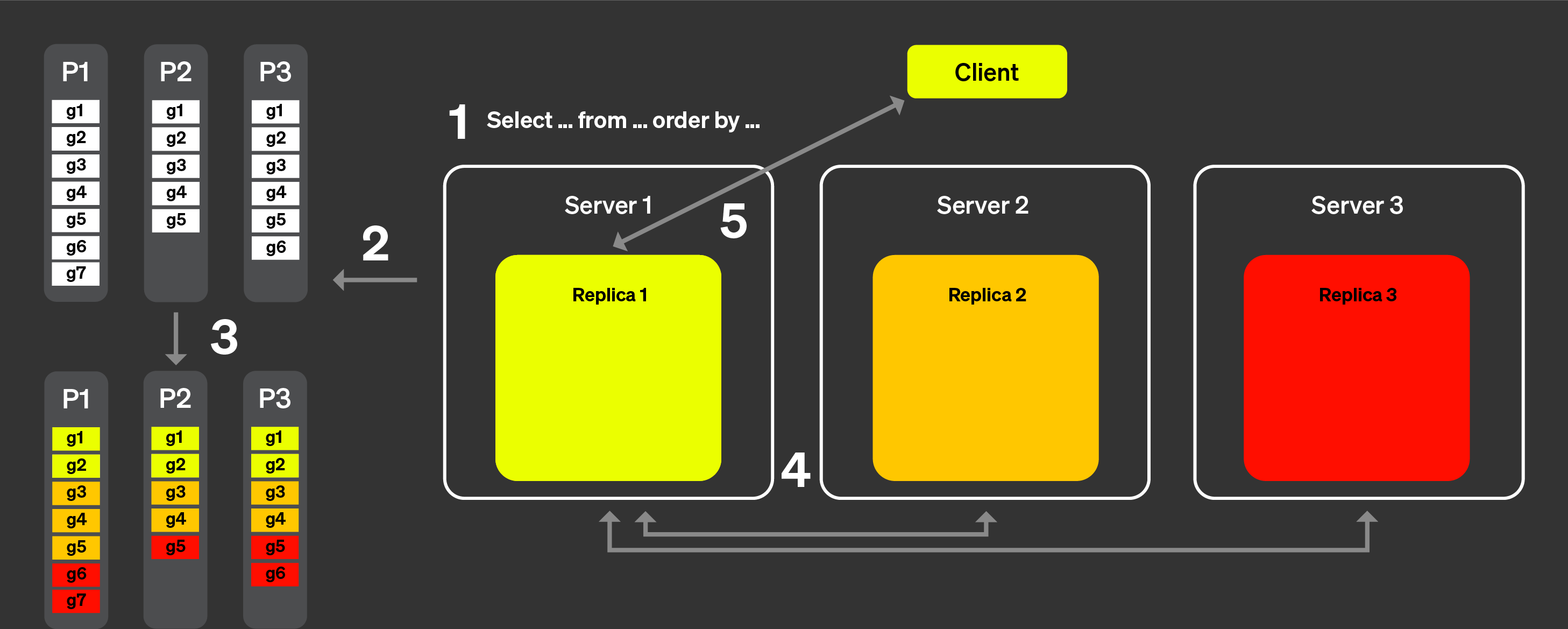
С параллельными репликами:
Запрос от клиента отправляется на один узел после прохождения через балансировщик нагрузки. Этот узел становится координатором для этого запроса.
Узел анализирует индекс каждой части и выбирает правильные части и гранулы для обработки.
Координатор разбивает рабочую нагрузку на набор гранул, которые могут быть назначены различным репликам.
Каждый набор гранул обрабатывается соответствующими репликами, и объединяемое состояние отправляется координатору, когда они заканчивают.
Наконец, координатор объединяет все результаты от реплик и затем возвращает ответ клиенту.
Шаги выше описывают, как работают параллельные реплики теоретически. Однако на практике существует множество факторов, которые могут помешать такой логике работать идеально:
Некоторые реплики могут быть недоступны.
Репликация в ClickHouse асинхронная, некоторые реплики могут не иметь одинаковых частей в какой-то момент времени.
Необходимо как-то обрабатывать задержку между репликами.
Кеш файловой системы варьируется от реплики к реплике в зависимости от активности каждой реплики, что означает, что случайное назначение задач может привести к менее оптимальной производительности из-за локальности кеша.
Мы исследуем, как эти факторы преодолеваются в следующих разделах.
Объявления
Чтобы решить (1) и (2) из списка выше, мы ввели концепцию объявления. Давайте визуализируем, как это работает, с помощью рисунка ниже:
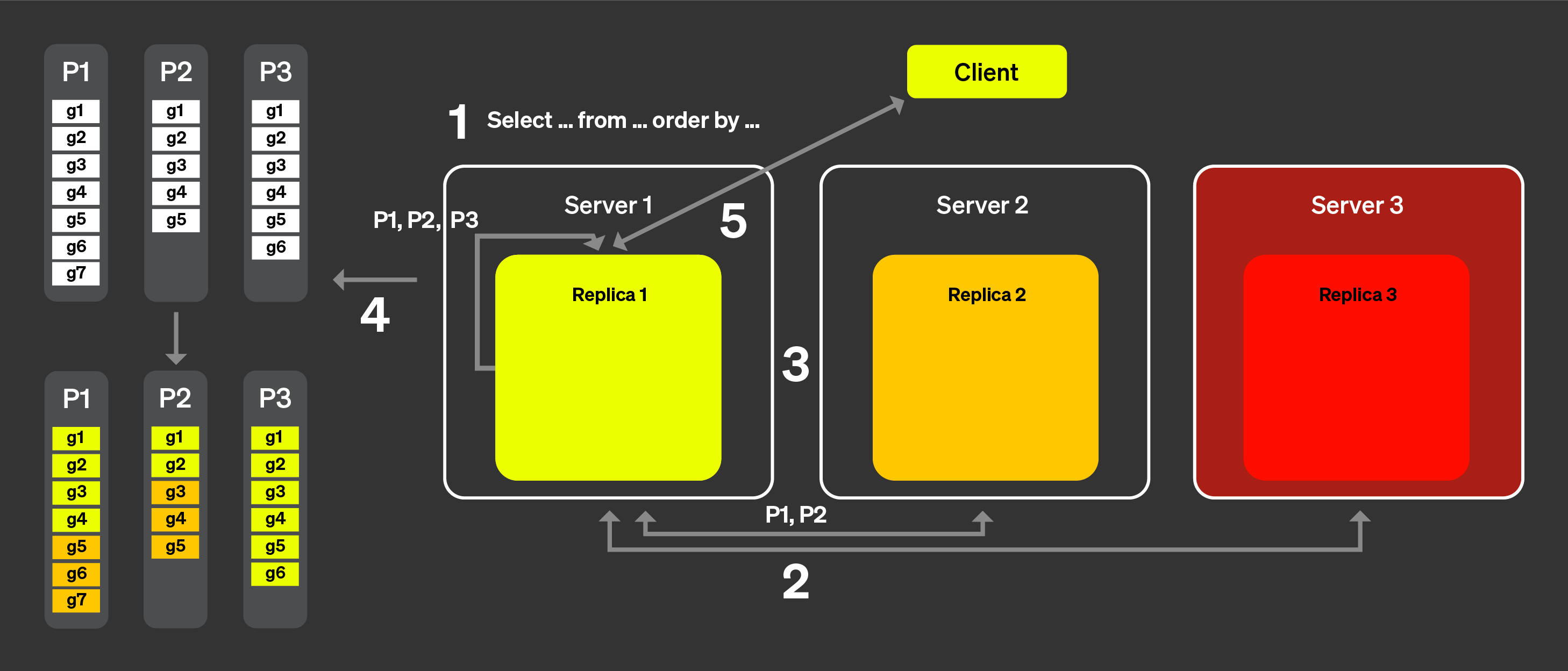
Запрос от клиента отправляется на один узел после прохождения через балансировщик нагрузки. Узел становится координатором для этого запроса.
Координирующий узел отправляет запрос на получение объявлений от всех реплик в кластере. Реплики могут иметь несколько разные представления текущего набора частей для таблицы. В результате нам нужно собрать эту информацию, чтобы избежать неправильных решений по расписанию.
Координирующий узел затем использует объявления, чтобы определить набор гранул, которые могут быть назначены различным репликам. Здесь, например, мы видим, что никакие гранулы из части 3 не были назначены реплике 2, потому что эта реплика не предоставила эту часть в своем объявлении. Также отмечаем, что никакие задачи не были назначены реплике 3, потому что реплика не предоставила объявление.
После того как каждая реплика обработала запрос на своем подмножестве гранул и объединяемое состояние было отправлено обратно координатору, координатор объединяет результаты и ответ отправляется клиенту.
Динамическое координирование
Чтобы решить проблему задержки, мы добавили динамическое координирование. Это означает, что все гранулы не отправляются реплике в одном запросе, но каждая реплика сможет запрашивать новую задачу (набор гранул для обработки) у координатора. Координатор даст реплике набор гранул на основе полученного объявления.
Предположим, что мы находимся на этапе процесса, когда все реплики отправили объявление со всеми частями.
Рисунок ниже визуализирует, как работает динамическое координирование:
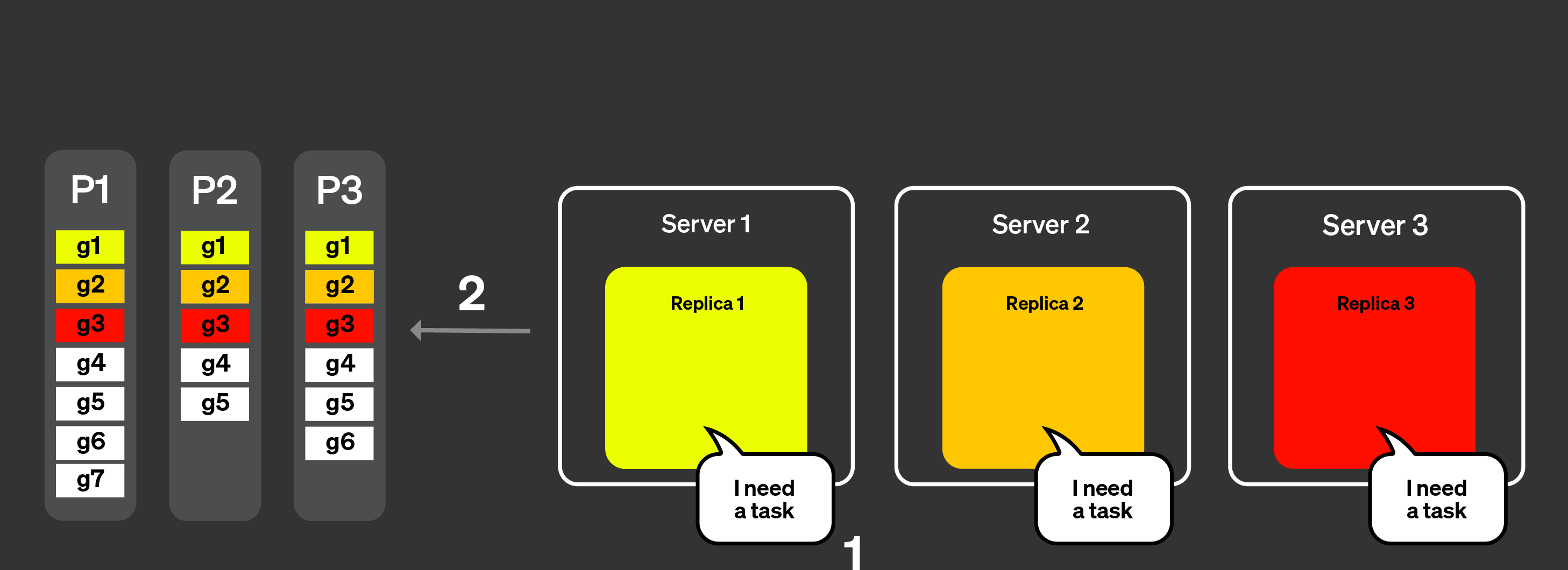
Реплики сообщают координатору, что они могут обрабатывать задачи, они также могут указать, сколько работы они могут выполнить.
Координатор назначает задачи репликам.
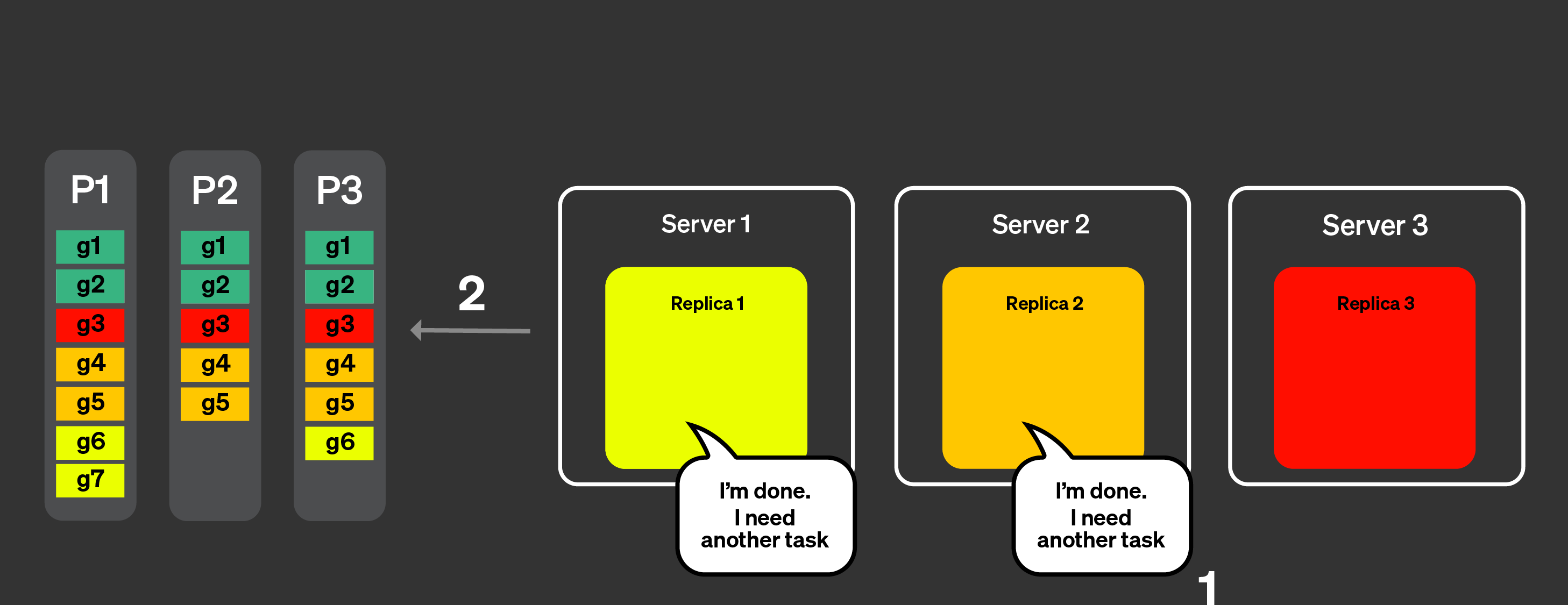
Реплики 1 и 2 могут очень быстро закончить свою задачу. Они запросят еще одну задачу у координатора.
Координатор назначает новые задачи реплике 1 и 2.
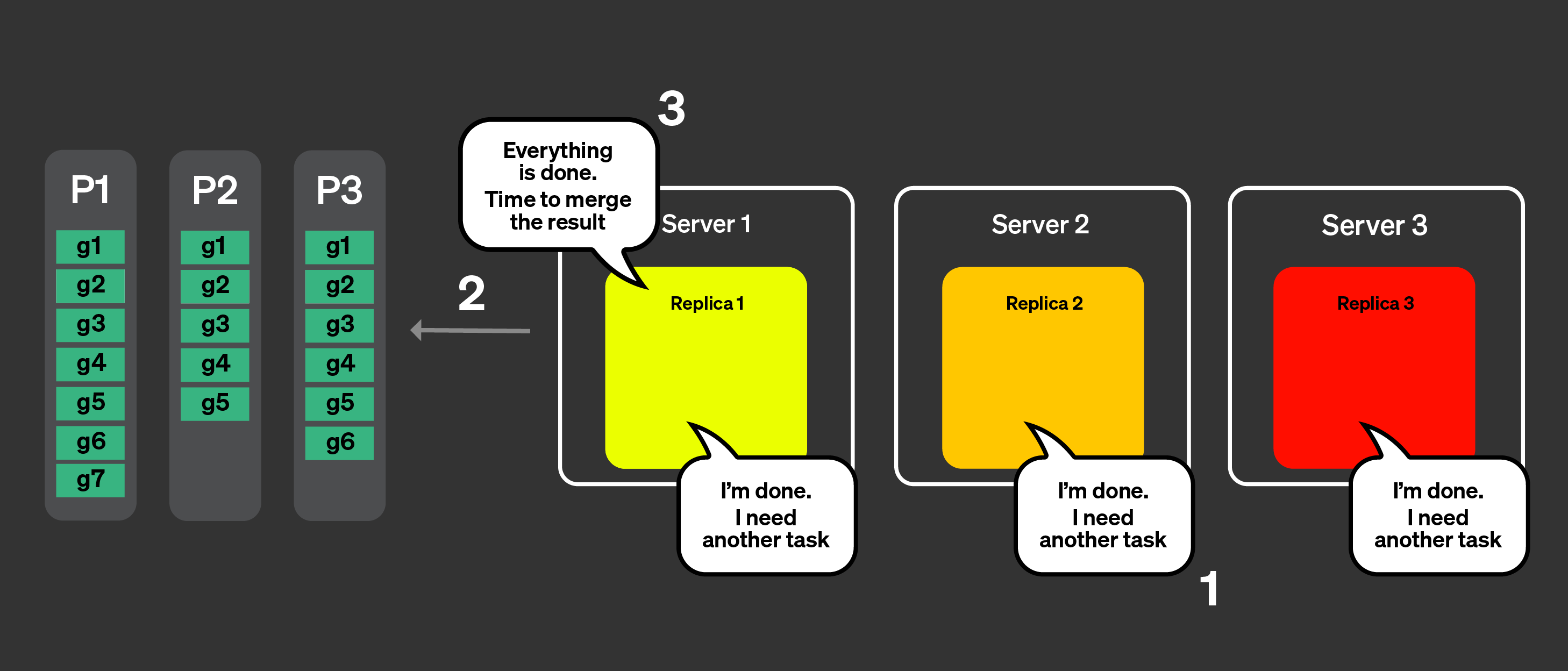
Все реплики теперь закончили обработку своей задачи. Они запрашивают больше задач.
Координатор, используя объявления, проверяет, какие задачи остаются для обработки, но не осталось оставшихся задач.
Координатор сообщает репликам, что все было обработано. Он теперь объединит все объединяемые состояния и ответит на запрос.
Управление локальностью кеша
Последним оставшимся потенциальным вопросом является то, как мы обрабатываем локальность кеша. Если запрос выполняется несколько раз, как мы можем гарантировать, что одна и та же задача будет направлена к одной и той же реплике? В предыдущем примере у нас были назначены следующие задачи:
| Реплика 1 | Реплика 2 | Реплика 3 | |
|---|---|---|---|
| Часть 1 | g1, g6, g7 | g2, g4, g5 | g3 |
| Часть 2 | g1 | g2, g4, g5 | g3 |
| Часть 3 | g1, g6 | g2, g4, g5 | g3 |
Чтобы гарантировать, что одни и те же задачи назначаются одним и тем же репликам и могут воспользоваться кешем, происходит две вещи. Вычисляется хеш части + набор гранул (задача). Применяется деление по модулю количества реплик для назначения задач.
На бумаге это звучит хорошо, но на практике резкая нагрузка на одну реплику или ухудшение сети могут привести к задержке, если одна и та же реплика постоянно используется для выполнения определенных задач. Если max_parallel_replicas меньше, чем количество реплик, то случайные реплики выбираются для выполнения запроса.
Кража задач
Если какая-либо реплика обрабатывает задачи медленнее других, другие реплики попытаются "украсть" задачи, которые в принципе принадлежат этой реплике по хешу, чтобы снизить задержку.
Ограничения
У этой функции есть известные ограничения, из которых основные документированы в этом разделе.
Если вы обнаружите проблему, которая не является одной из перечисленных ограничений, и подозреваете, что параллельные реплики являются причиной, пожалуйста, откройте проблему на GitHub, используя метку comp-parallel-replicas.
| Ограничение | Описание |
|---|---|
| Сложные запросы | В настоящее время параллельные реплики работают довольно хорошо для простых запросов. Сложные конструкции, такие как CTE, подзапросы, JOIN, не плоские запросы и т. д., могут негативно сказаться на производительности запросов. |
| Малые запросы | Если вы выполняете запрос, который не обрабатывает много строк, выполнение его на нескольких репликах может не дать лучшего времени выполнения, учитывая, что время сети на координацию между репликами может привести к дополнительным циклам в выполнении запроса. Вы можете ограничить эти проблемы, используя настройку: parallel_replicas_min_number_of_rows_per_replica. |
| Параллельные реплики отключены с FINAL | |
| Данные с высокой кардинальностью и сложная агрегация | Высоко кардинальная агрегация, которая требует отправки большого объема данных, может значительно замедлить ваши запросы. |
| Совместимость с новым аналитиком | Новый аналитик может значительно замедлить или ускорить выполнение запроса в конкретных сценариях. |
Настройки, связанные с параллельными репликами
| Настройка | Описание |
|---|---|
enable_parallel_replicas | 0: отключено1: включено 2: Принудительно использование параллельной реплики, выбросит исключение, если не используется. |
cluster_for_parallel_replicas | Имя кластера, которое следует использовать для параллельной репликации; если вы используете ClickHouse Cloud, используйте default. |
max_parallel_replicas | Максимальное количество реплик, используемых для выполнения запроса на нескольких репликах, если указано число меньше количества реплик в кластере, узлы выбираются случайным образом. Это значение также может быть пересмотрено, чтобы учесть горизонтальное масштабирование. |
parallel_replicas_min_number_of_rows_per_replica | Помогает ограничить количество реплик, используемых на основе числа строк, которые необходимо обработать. Количество используемых реплик определяется: предполагаемое количество строк для чтения / минимальное количество строк на реплику. |
allow_experimental_analyzer | 0: используйте старый анализатор1: используйте новый анализатор. Поведение параллельных реплик может изменяться в зависимости от используемого анализатора. |
Расследование проблем с параллельными репликами
Вы можете проверить, какие настройки используются для каждого запроса в таблице
system.query_log. Вы также можете
посмотреть на таблицу system.events,
чтобы увидеть все события, произошедшие на сервере, и вы можете использовать
табличную функцию clusterAllReplicas, чтобы увидеть таблицы на всех репликах
(если вы облачный пользователь, используйте default).
Ответ
Таблица system.text_log также
содержит информацию о выполнении запросов с использованием параллельных реплик:
Ответ
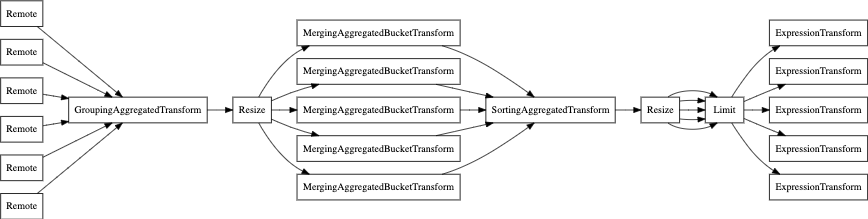
Наконец, вы также можете использовать EXPLAIN PIPELINE. Он демонстрирует, как ClickHouse
будет выполнять запрос и какие ресурсы будут использованы для
выполнения запроса. Рассмотрим следующий запрос в качестве примера:
Давайте посмотрим на конвейер запроса без параллельной реплики:

А теперь с параллельной репликой: